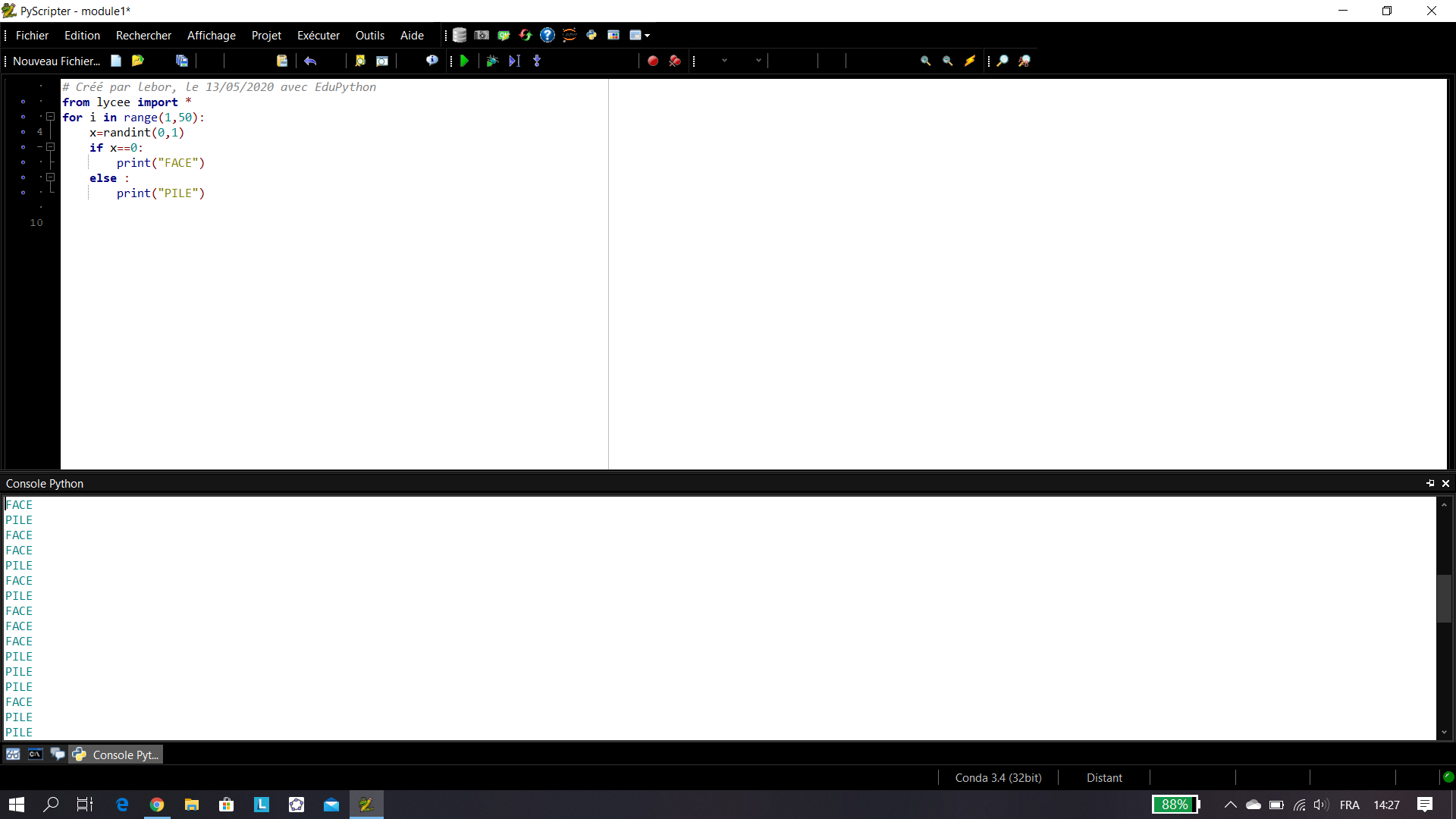
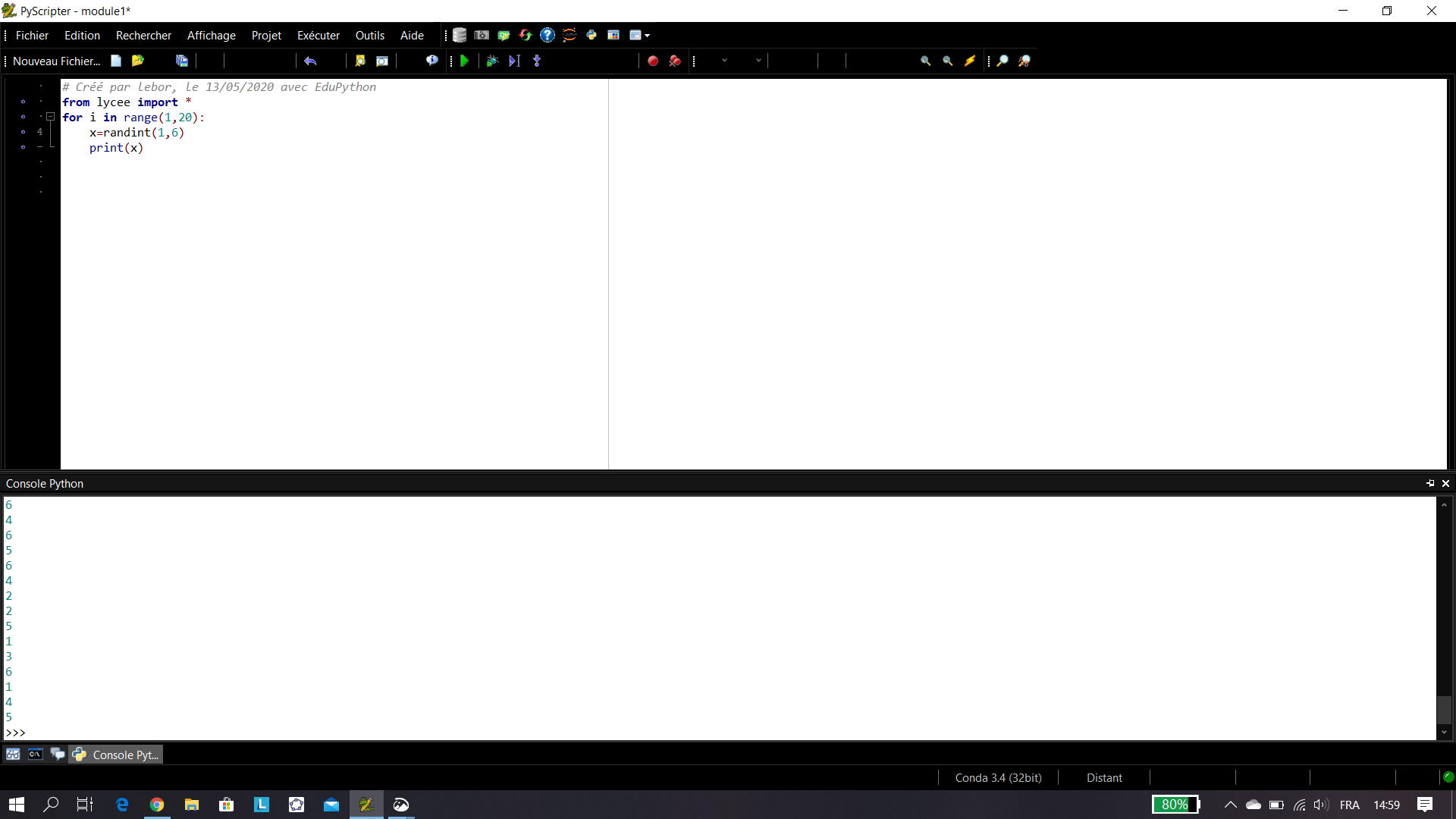
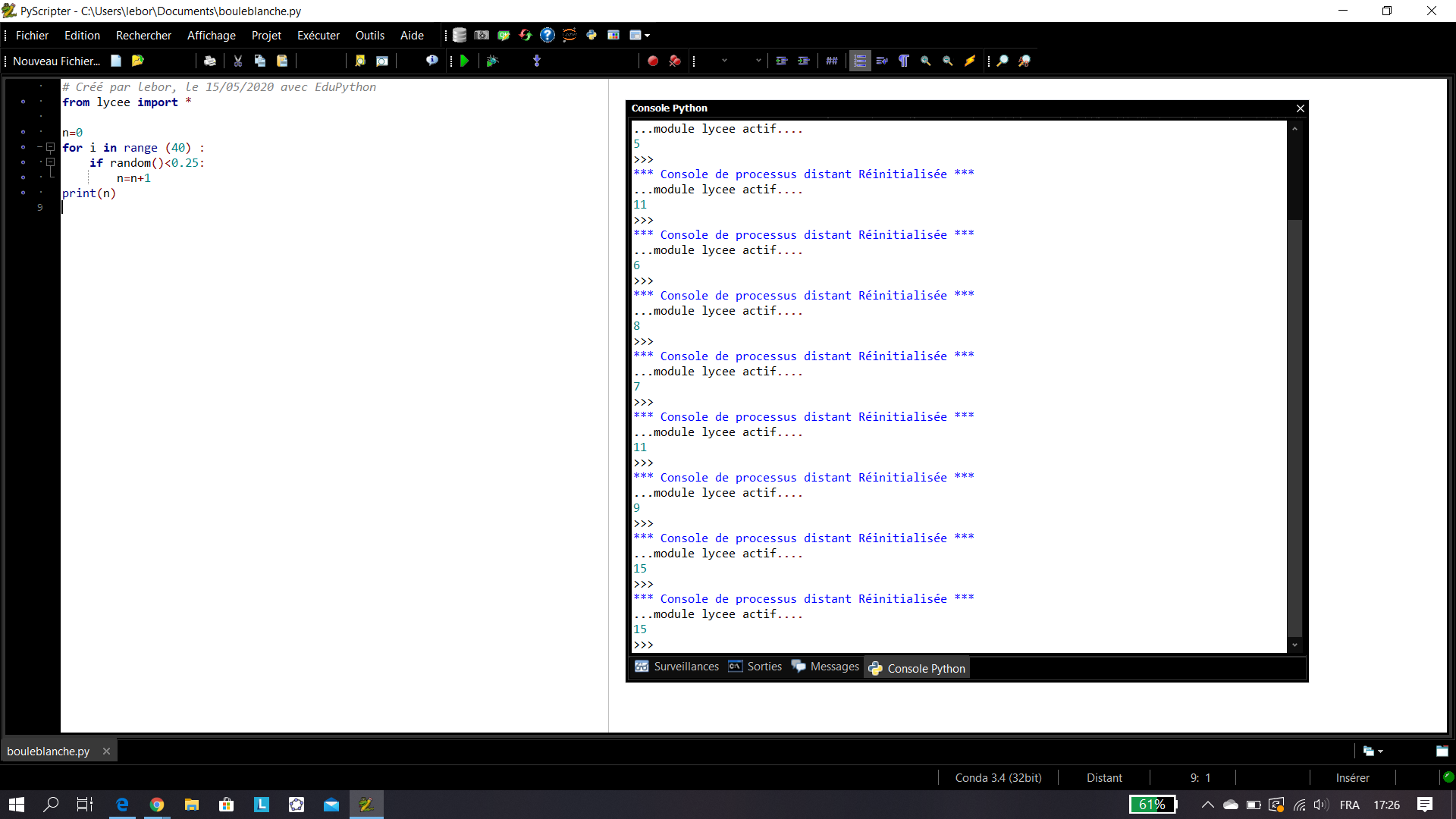
Pour le premier échantillon : La fréquence d’apparition de « boule blanche » est \frac{5}{40}=0.125.
Pour le second échantillon : La fréquence d’apparition de « boule blanche » est \frac{11}{40}=0.275.
Pour le troisième échantillon : La fréquence d’apparition de « boule blanche » est \frac{6}{40}=0.15.
Pour le quatrième échantillon : La fréquence d’apparition de « boule blanche » est \frac{8}{40}=0.2.
Pour le cinquième échantillon : La fréquence d’apparition de « boule blanche » est \frac{7}{40}=0.175.
Pour le sixième échantillon : La fréquence d’apparition de « boule blanche » est \frac{11}{40}=0.275.
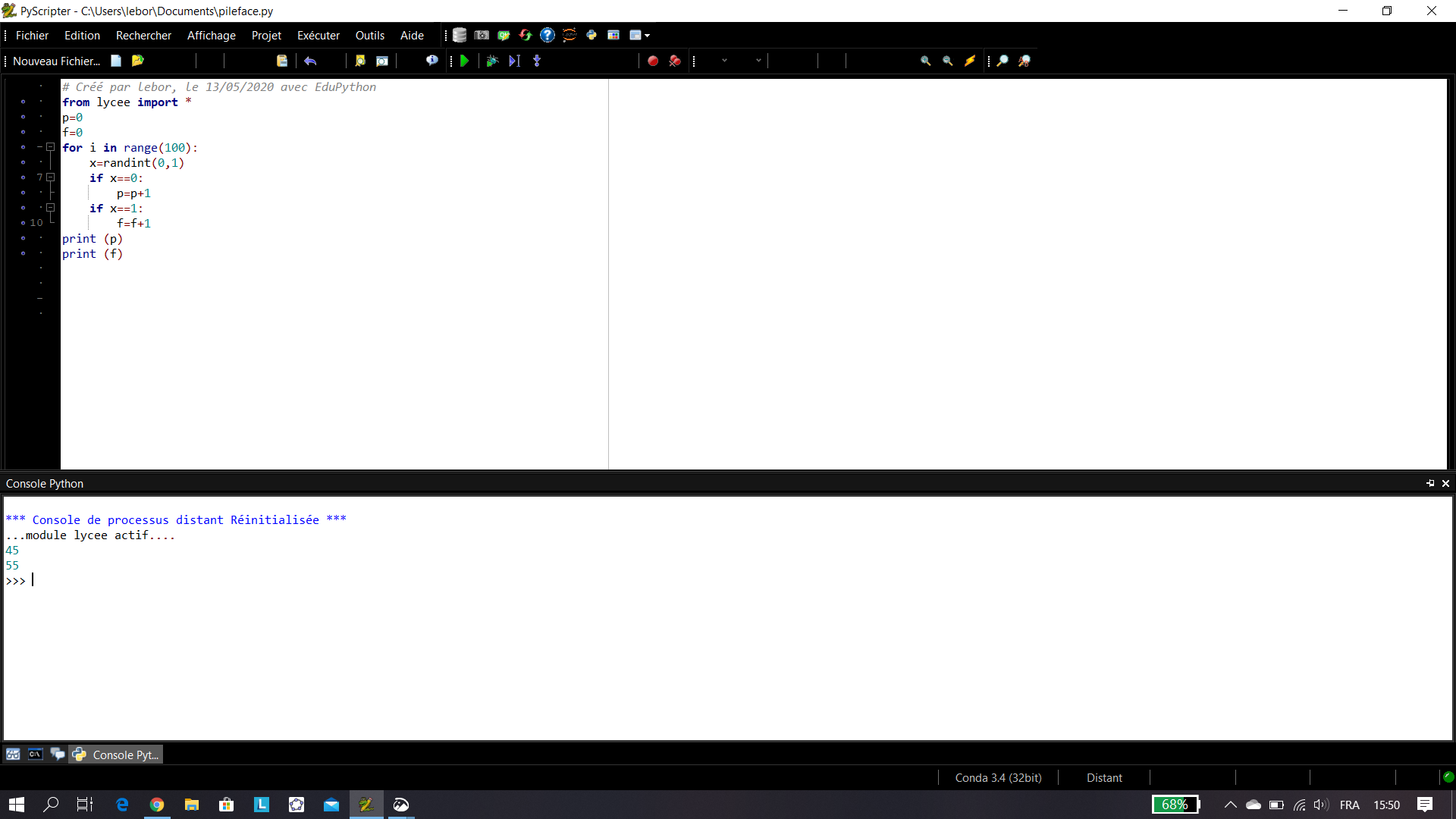
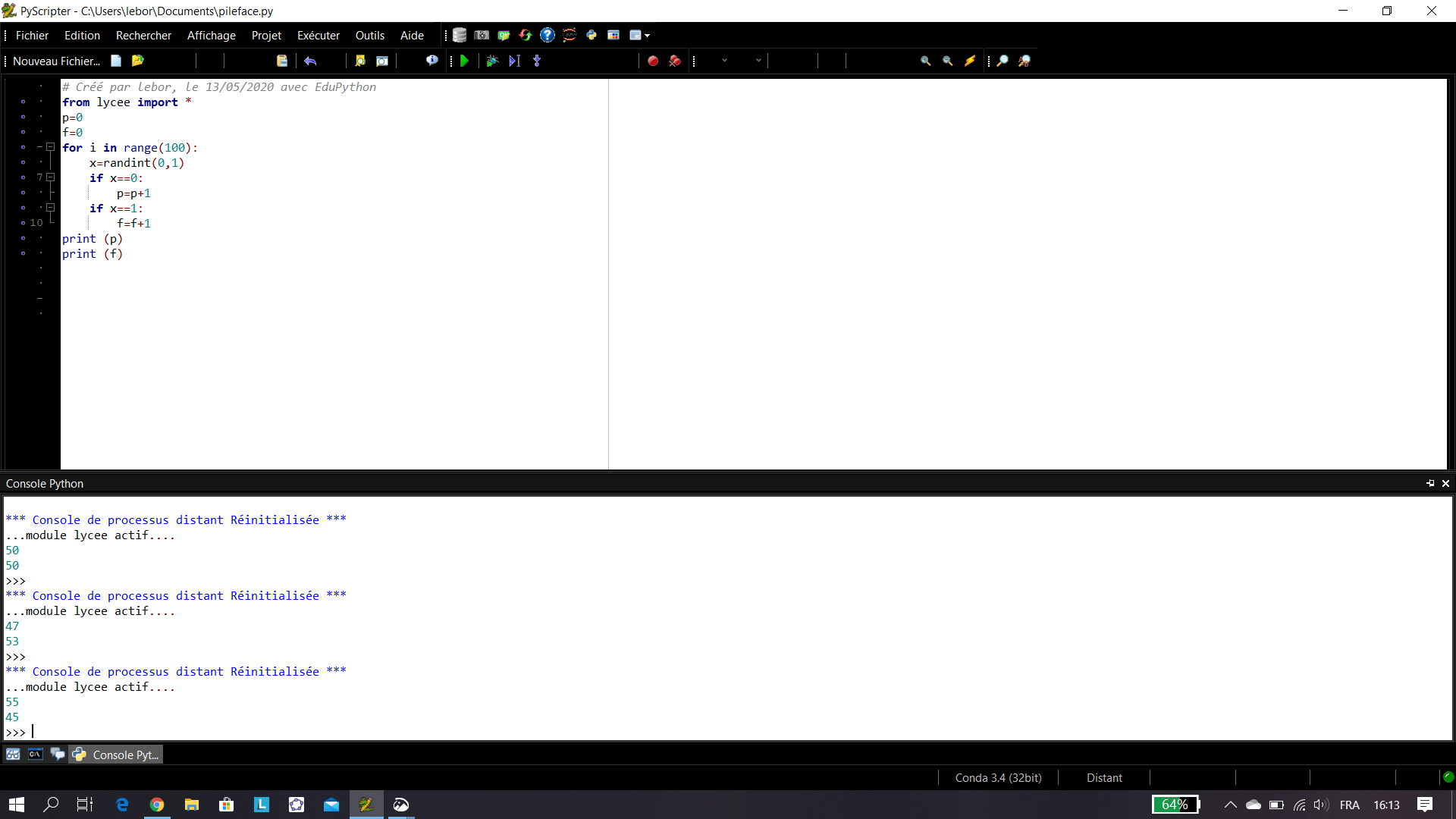
On constate que les fréquences obtenues fluctue autour de la proportion p=\frac{1}{4}=0.25. Il s’agit de la fluctuation d’échantillonnage.
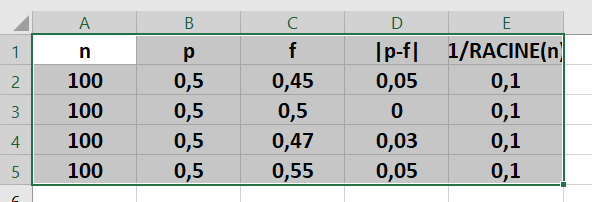
Remarque : En général, |p-f|\leq \frac{1}{\sqrt n}.
C’est effectivement ce qu’on observe en comparant les résultats des deux dernières colonnes dans le tableur Excel ci-dessous.